
رمزگشایی سیستم Helpful Content گوگل بر اساس اسناد فاششده
بازمهندسی تولید محتوای مفید، قابل اعتماد و انسانمحور
در این بخش، گوگل توضیح میدهد که سیستمهای رتبهبندیاش چگونه تشخیص میدهند کدام محتوا واقعاً «مفید» است و کدام محتوا صرفاً برای گرفتن رتبه ساخته شده.
این یکی از مهمترین بخشهای گایدلاین است، چون در اسناد فنی و لیکهای منتشرشده هم دقیقاً همین مفاهیم با نامهای مهندسیشده دیده میشوند.
گوگل میگوید اولویت سیستمهای رتبهبندیاش با:
- محتوای مفید
- محتوای قابل اعتماد
- محتوای انسانمحور
است؛ محتوایی که هدفش کمک کردن باشد، نه دستکاری رتبه.
در لایه فنی، این سه مفهوم به چند سیگنال داخلی تبدیل شدهاند که در لیک Content Warehouse هم دیده میشوند و نشان میدهند این صحبتها فقط یک توصیه مبهم نیست، بلکه پیادهسازی واقعی دارند.
سیگنالهایی که نشان میدهند محتوا مفید و قابل اعتماد است.
Q*: امتیاز اعتماد و کیفیت صفحه. این سیگنال تعیین میکند صفحه از دید گوگل چقدر قابل اتکا و ارزشمند است.
siteAuthority: اعتبار کلی دامنه در میان وب. نشان میدهد این سایت چقدر سابقه، ثبات و مرجعیت دارد.
predictedDefaultNsr: مدلی که ارزش محتوایی صفحه را نسبت به سایر نتایج میسنجد و تخمین میزند صفحه چقدر احتمال دارد برای کاربر مفید باشد.
P*: میزان انسانمحور بودن محتوا؛ اینکه متن از نظر ساختار، عمق و رفتار کاربری، حاصل تلاش انسانی است یا تولید انبوه و ماشینی
سیگنالهایی که نشان میدهند محتوا برای دستکاری رتبه ساخته شده.
SpamBrain: سیستم اصلی گوگل برای شناسایی الگوهای اسپمی؛ هم محتوا را بررسی میکند و هم الگوهای تولید، ساختار، لینکسازی و حتی رفتار کاربر را.
DocLevelSpamScore: امتیاز اسپمی هر صفحه بهصورت مجزا. اگر صفحه از نظر تکرار، سطحی بودن، الگوهای تولید سریع یا فقدان اصالت مشکوک باشد، این امتیاز بالا میرود.
spamrank: شاخص احتمال دستکاری در رتبه؛ یعنی آیا از دید گوگل این محتوا برای کمک به کاربر نوشته شده یا هدفش فقط گرفتن رتبه بوده.
به زبان ساده:
گوگل در این بخش دارد میگوید: محتوایی دست بالا را میگیرد که اولویت اصلیاش کمک به کاربر باشد.
و اگر هدف محتوا گرفتن رتبه باشد، سیگنالهای اسپم فعال میشوند و محتوا امتیاز منفی میگیرد.
این همان تفاوت محتوای انسانمحور و محتوای Search-Engine-First است.
ارزیابی محتوای خودتان
در ادامه، گوگل توصیه میکند که اگر صفحهای افت کرده، اولین کار این است که خودمان آن را با همین معیارها ارزیابی کنیم. این یک جمله ساده در ظاهر است، اما در عمل یکی از مهمترین نکات سئو است.
گوگل میگوید:
افتهایی را که تجربه کردهاید بررسی کنید و ببینید این صفحات چطور در برابر پرسشهای این بخش ارزیابی میشوند.
معنی عملی این جمله این است:
- وقتی صفحهای افت میکند، ۹۰ درصد مواقع مشکل در خود محتواست.
- محتوا یا عمق ندارد.
- یا ارزش افزوده ایجاد نمیکند.
- یا نشانههای محتوای ماشینی و سریعنویسی در آن دیده میشود.
- یا ساختار صفحه طوری است که کاربر دوباره مجبور میشود سرچ کند.
این همان چیزی است که گوگل با سیستمهای رفتاری مثل goodClicks و badClicks اندازه میگیرد.
بنابراین اولین کاری که باید انجام داد این است که:
- صفحه افتکرده را کنار معیارهای کیفیت قرار بدهیم
- ببینیم محتوا از نظر اصالت، دقت، عمق، تجربه و انسانمحور بودن چه جایگاهی دارد.
- ببینیم آیا ارزش این صفحه در مقایسه با صفحات رقیب قابل دفاع است یا نه.
این همان چیزی است که گوگل از آن بهعنوان self-assessment یاد میکند.
به زبان خودت:
گوگل نمیگوید برو تکنیکال را چک کن.
میگوید برو ببین خود محتوا چقدر استاندارد است.

پرسشهای کیفیت محتوا؛
معیارهای اصلی گوگل برای سنجش ارزش واقعی صفحات
در این بخش، گوگل معیارهایی را مطرح میکند که بر اساس آنها تشخیص میدهد یک محتوا چقدر «اصیل»، «مفید» و «قابل اتکا» است.
این پرسشها در ظاهر سادهاند، اما پشت هرکدام سیگنالهای مهندسیشده و واقعی وجود دارد که در لیک Content Warehouse دیده شدهاند.
به بیان ساده، این بخش نقشهای است برای اینکه بفهمیم چرا یک محتوا رشد میکند و دیگری سقوط.
آیا محتوا اطلاعات، گزارش، تحقیق یا تحلیل اصیل ارائه میکند؟
OriginalContentScore: امتیاز اصالت محتوا. اگر بخش زیادی از متن بازنویسی منابع دیگر باشد یا ارزش جدیدی ارائه نکند، این سیگنال پایین میآید.
contentEffort: نشان میدهد چه مقدار تلاش واقعی برای تولید محتوا انجام شده. محتواهای عجلهای، سطحی و بدون عمق معمولاً امتیاز پایین دارند.
این معیار اساساً سنجش «تلاش انسانی» است.
گوگل به محتوایی امتیاز میدهد که حاصل فکر، تجربه یا تحلیل باشد؛ نه ترکیبی از چند مقاله دیگر.
آیا محتوا توضیحی کامل، جامع و عمیق از موضوع ارائه میدهد؟
contentEffort: (همان سیگنال تلاش انسانی که بالاتر توضیح دادیم؛ اینجا در عمق پوشش موضوع هم اثر دارد).
bodyWordsToTokensRatio: نسبت متن واقعی به توکنها را بررسی میکند. متنهایی که با کلمات اضافی پف شده باشند امتیاز پایین میگیرند.
QBST: کیفیت بلوکهای محتوایی را بررسی میکند؛ یعنی آیا ساختار منطقی، پیوسته و کامل است یا نه.
این بخش نشان میدهد آیا محتوا واقعاً به یک سؤال پاسخ میدهد یا فقط چند پاراگراف پراکنده است.
آیا محتوا نکات، تحلیل یا اطلاعاتی فراتر از موارد بدیهی ارائه میکند؟
این معیار برای تشخیص محتواهای سطحی است.
گوگل به دنبال محتوایی است که insight ارائه کند؛
چیزی که خواننده پس از مطالعه بگوید «این قسمت را نمیدانستم.»
محتوایی که فقط توضیح واضحات باشد، در این بخش امتیاز نمیگیرد.
اگر محتوا از منابع دیگر استفاده کرده، آیا فقط بازنویسی نیست و ارزش افزوده ایجاد میکند؟
shingleInfo: الگوی شباهت جملات به منابع دیگر را بررسی میکند.
OriginalContentScore: اگر نویسنده از منابع استفاده کرده اما تحلیل، تجربه یا ارزش جدید اضافه کرده باشد، این امتیاز بالا میرود.
copycatScore: اگر محتوا فقط بازنویسی باشد (بدون ارزش افزوده)، این سیگنال بالا میرود و صفحه کیفیت پایین محسوب میشود.
این همان جایی است که گوگل تولید انبوه محتوای AI و بازنویسیهای بدون ارزش را شناسایی میکند.
آیا عنوان صفحه خلاصهای دقیق و مفید از محتوا ارائه میدهد؟
titlematchScore: بررسی میکند آیا عنوان با محتوای صفحه هماهنگ است یا خیر.
goldminePageScore: ارزش اطلاعاتی صفحه را میسنجد و به تایتل درست وزن مثبت میدهد.
عنوان باید تصویر واقعی و بدون اغراق از محتوا ارائه کند.
عنوان غلط یا کلیکبیتی امتیاز کیفیت را کاهش میدهد.
آیا عنوان از اغراق، شوک یا کلیکبیت دوری میکند؟
BadTitleInfo: نشانهای برای تشخیص عنوان گمراهکننده، احساسی یا بیشازحد تبلیغاتی.
serpDemotion: اگر عنوان گولزننده باشد، صفحه مستقیماً افت رتبه میگیرد.
اینجا گوگل صریح میگوید: تایتل غلط مساوی افت رتبه.
آیا محتوای صفحه از آن نوعی است که کاربر بخواهد آن را ذخیره کند یا به اشتراک بگذارد؟
goodClicks: نشان میدهد کاربر بعد از کلیک تجربه خوبی داشته یا سریع برگشته
socialgraphNodeNameFp: سطح اشتراکگذاری و تعامل اجتماعی صفحه را اندازه میگیرد.
اگر محتوایی ارزش واقعی داشته باشد، کاربران آن را ذخیره میکنند، برای دیگران میفرستند یا دوباره به آن برمیگردند.
آیا این محتوا نسبت به سایر صفحات موجود در نتایج، ارزش بیشتری ارائه میکند؟
predictedDefaultNsr: (همان سیگنال پیشبینی ارزش که بالاتر گفتیم؛ اینجا در مقایسه با رقبا استفاده میشود).
QualityBoost: اگر صفحه نسبت به رقبا بهطور چشمگیر بهتر باشد، این تقویتکننده فعال میشود.
یعنی گوگل مستقیماً محتوا را در برابر رقبا میگذارد و بررسی میکند کدامیک بهتر به نیاز کاربر پاسخ میدهد.
آیا محتوا از نظر نگارشی، املایی یا ساختاری مشکل دارد؟
lowQuality: کیفیت پایین نگارش، جملهبندی و ساختار کلی را تشخیص میدهد.
gibberishScores: محتوای ماشینی، بیمعنی یا تولید انبوه را شناسایی میکند.
حتی اگر محتوا درست باشد، کیفیت نوشتار پایین باعث افت امتیاز میشود.
آیا محتوا بهصورت انبوه، صنعتی یا توسط شبکه بزرگی از تولیدکنندگان منتشر شده است؟
numOfUrlsByPeriods: تعداد محتواهای منتشرشده در بازههای زمانی مشخص را میسنجد. تولید بیش از حد سریع نشانه اسپم است.
fireflySiteSignal: الگوهای تولید صنعتی، شبکهای یا انتشار محتوا روی تعداد زیاد سایت را تشخیص میدهد.
این همان جایی است که گوگل سایتهای محتوای انبوه را علامتگذاری میکند.
پرسشهای تخصص و اعتماد (Expertise Questions)
در این بخش، گوگل معیارهایی را معرفی میکند که برای سنجش «تخصص»، «اعتبار» و «اعتمادپذیری» محتوا استفاده میشود.
این معیارها مستقیماً با مفهوم E-E-A-T در ارتباط هستند.
آیا محتوا اطلاعات را طوری ارائه میکند که باعث جلب اعتماد شود؟
(منابع روشن، شواهد تخصص، توضیح درباره نویسنده یا سایت)
siteAuthority: (همان اعتبار کلی دامنه که بالاتر توضیح دادیم؛ اینجا در بُعد اعتماد هم نقش دارد).
authorObfuscatedGaiaStr: تشخیص اینکه نویسنده واقعی است یا پنهان/نامعلوم.
isAuthor: نشان میدهد آیا صفحه نویسنده مشخص و قابل شناسایی دارد یا خیر.
spamrank: اگر سایت یا نویسنده سابقه رفتار اسپمی داشته باشد، این سیگنال افزایش پیدا میکند و اعتماد پایین میآید.
محتوایی قابل اعتماد است که:
- منبع دارد
- نویسنده شفاف است
- تخصص نویسنده مشخص است
- و سایت سابقه بد یا رفتار مشکوک ندارد
اگر کسی سایت را بررسی کند، آیا آن را معتبر و شناختهشده خواهد یافت؟
siteAuthority: (همان سیگنال اعتبار دامنه)
predictedDefaultNsr: مدل پیشبینی ارزش صفحه و سایت در قیاس با رقبا.
اعتمادپذیری فقط مربوط به یک صفحه نیست؛
گوگل وبسایت را بهعنوان یک موجودیت نگاه میکند:
آیا این سایت در کل، معتبر و شناختهشده است؟
آیا این محتوا توسط یک متخصص یا فردی نوشته یا بررسی شده که موضوع را بهخوبی میشناسد؟
authorReputationScore: اعتبار نویسنده در سطح وب و سابقه تولید محتوای مفید.
siteFocusScore: تمرکز موضوعی سایت؛ هرچه سایت روی یک حوزه خاص متمرکزتر باشد، در همان حوزه اعتبار بیشتری میگیرد.
این همان مفهوم Expertise است:
محتوای تخصصی باید توسط فردی نوشته شود که واقعاً موضوع را میفهمد، نه کسی که چند مقاله را کنار هم چیده.
آیا محتوا اشتباه factual (قابل بررسی) دارد؟
consensus_score: میزان سازگاری اطلاعات صفحه با منابع معتبر و دادههای شناختهشده در وب.
is_debunking_query: تشخیص اینکه آیا محتوا روی موضوعات حساس/شایعات/اطلاعات غلط کار میکند و نیاز به بررسی مضاعف دارد.
اشتباهات factual حتی کوچک، امتیاز اعتماد را بهشدت کاهش میدهد.

ارائه یک تجربه کاربری عالی در صفحه
(Provide a Great Page Experience)
در این بخش، گوگل توضیح میدهد که کیفیت تجربه کاربری صفحه (Page Experience) فقط یک «فاکتور جانبی» نیست؛
بلکه بخشی از هسته سیستمهای رتبهبندی است.
یعنی اگر صفحه تجربه کاربری ضعیف داشته باشد، حتی محتوای خوب هم نمیتواند رتبه مطلوب بگیرد.
گوگل میگوید سیستمهای رتبهبندیاش به صفحاتی که تجربه کاربری خوبی ارائه بدهند، پاداش میدهند؛
یعنی این بخش در دسته سیگنالهای مثبت (reward) است، نه فقط جریمه.
گوگل به چه چیزی پاداش میدهد؟
IndexingMobileVoltVoltPerDocData: نشان میدهد صفحه از نظر نسخه موبایل، سرعت رندر و بارگذاری عناصر اصلی چه وضعیتی دارد.
با توجه به mobile-first بودن، صفحه کند یا ناپایدار در موبایل امتیاز تجربه کاربری پایینی میگیرد.
به بیان ساده:
اگر صفحه در موبایل خوب کار نکند، محتوای خوب هم نمیتواند پاداش بگیرد.
صاحبان سایت باید چه چیزهایی را بررسی کنند؟
mobileCwv: امتیازهای Core Web Vitals نسخه موبایل (LCP، CLS، INP) بر اساس داده کاربران واقعی.
inp: تأخیر در پاسخگویی صفحه هنگام تعامل کاربر (کلیک، اسکرول، اینتراکشنها).
cls: ثبات چیدمان صفحه هنگام بارگذاری. جابهجایی المانها تجربه را خراب میکند.
این معیارها نشان میدهند Page Experience فقط «سرعت» نیست؛
گوگل کیفیت واقعی تعامل کاربر با صفحه را اندازه میگیرد.
گوگل در این بخش میگوید:
اگر تجربه کاربری صفحه خوب نباشد، محتوای خوب هم نمیتواند به رتبه مناسب برسد.
بنابراین کیفیت محتوا و UX باید با هم تنظیم شوند:
- سرعت
- ثبات
- تعامل
- نسخه موبایل
- عملکرد عناصر
اینها بخش جداییناپذیر کیفیت صفحه هستند.
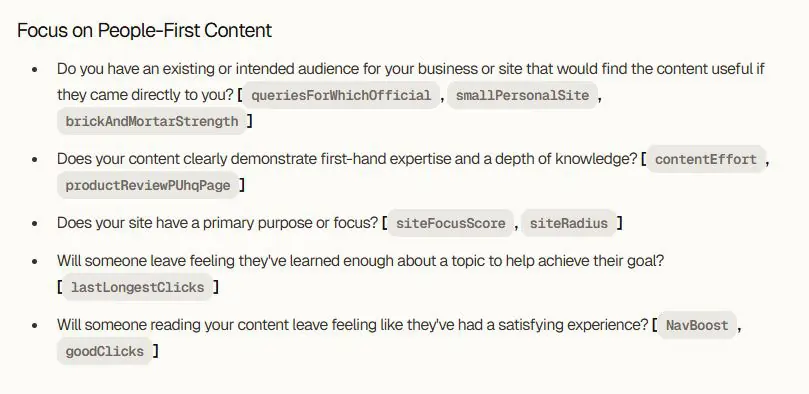
تمرکز بر محتوای انسانمحور
(Focus on People-First Content)
در این بخش، گوگل توضیح میدهد که محتوای «انسانمحور» چیست و چه معیارهایی دارد.
منظور این است که محتوا برای مخاطب واقعی نوشته شده باشد، نه برای جلب رضایت الگوریتم.
هر سؤال این بخش پشتصحنهاش سیگنالهای دقیقی دارد که در لیک Content Warehouse دیده شدهاند؛
یعنی این فقط توصیه نیست، بلکه بخشی از معماری الگوریتم است.
آیا کسبوکار یا سایت شما مخاطب واقعی دارد که اگر مستقیم به سراغتان بیاید، این محتوا برای او مفید باشد؟
queriesForWhichOfficial: نشان میدهد آیا کاربران واقعاً دنبال برند، سایت یا موجودیت شما هستند یا نه.
smallPersonalSite: سیگنالی مربوط به سایتهای کوچک شخصی که معمولاً محتوای کمتر صنعتی و واقعیتر دارند.
brickAndMortarStrength: قدرت حضور واقعی (فیزیکی/معتبر) کسبوکار را نشان میدهد.
تحلیل:
محتوای انسانمحور یعنی اگر کاربر مستقیماً بیاید سراغ شما، همین محتوا برایش مفید باشد؛
نه اینکه فقط از طریق یک کلمهکلیدی وارد شود و محتوا ربط واقعی به نیازش نداشته باشد.
آیا محتوای شما تجربه مستقیم و دانش عمیق را نشان میدهد؟
contentEffort: (همان سیگنال تلاش انسانی؛ اینجا در قالب تجربه و عمق دانش دیده میشود).
productReviewPUhqPage: در نقد محصول، نشان میدهد آیا محصول واقعاً تست شده یا فقط اطلاعات از جاهای دیگر جمع شده.
گوگل به دنبال محتوایی است که نویسنده خودش «درگیر» موضوع بوده؛ تجربه شخصی، تست، تحلیل واقعی، مثال عملی و...
آیا سایت شما یک هدف یا تمرکز مشخص دارد؟
siteFocusScore: تمرکز موضوعی سایت را اندازه میگیرد. سایتی که درباره همهچیز مینویسد، امتیاز پایین میگیرد.
siteRadius: پهنای موضوعات سایت؛ هرچه شعاع محتوایی بزرگتر باشد، تمرکز کمتر است.
سایت باید در یک محدوده مشخص فعالیت کند.
محتوای انسانمحور معمولاً در سایتهای متمرکز تولید میشود، نه در سایتهای همهکاره.
آیا مخاطب بعد از خواندن محتوا احساس میکند «به اندازه کافی یاد گرفته» تا هدفش را پیش ببرد؟
lastLongestClicks: رفتار کاربر نشان میدهد آیا در صفحه میماند، عمقی میخواند و به نتیجه میرسد یا بعد از چند ثانیه برمیگردد.
گوگل از روی رفتار کاربر میفهمد محتوا کامل بوده یا نه.
اگر کاربر مجبور شود دوباره سرچ کند، یعنی محتوا ناقص است.
آیا مخاطب بعد از خواندن صفحه احساس «رضایت» دارد؟
NavBoost: سیگنال رفتاری بسیار مهم؛ اگر کاربران بعد از ورود رفتار مثبت (ماندگاری، تعامل، کلیک) داشته باشند، این سیگنال تقویت میشود.
goodClicks: کلیکهایی که با تجربه خوب همراه بودهاند؛ برگشت سریع و pogo-sticking این سیگنال را خراب میکند.
رضایت کاربر یعنی صفحه نه فقط جواب سؤال را داده، بلکه تجربه خوبی هم ایجاد کرده.
این همان چیزی است که گوگل در زبان رباتی با NavBoost و goodClicks اندازه میگیرد.
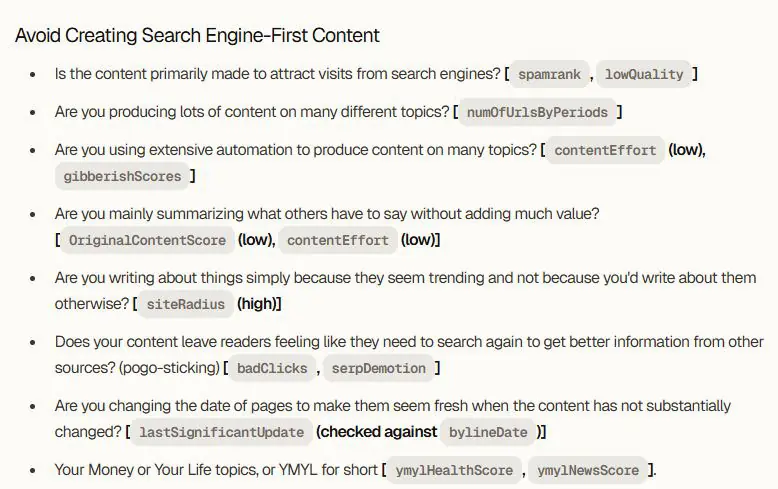
از تولید محتوای Search-Engine-First پرهیز کنید
(Avoid Creating Search Engine-First Content)
در این قسمت، گوگل توضیح میدهد که چه نوع محتوا از دید سیستمهای رتبهبندی «برای موتور جستجو» نوشته شده، نه برای انسان.
این معیارها فقط توصیه نیستند؛ پشت هرکدام یک سیگنال مهندسیشده وجود دارد.
محتوای Search-Engine-First عملاً فاقد ارزش انسانی است و سیستمهای گوگل آن را یا ایگنور میکنند یا بهصورت تدریجی افت میدهد.
آیا محتوا صرفاً برای جذب ورودی موتور جستجو ساخته شده؟
spamrank: (همان شاخص احتمال دستکاری رتبه؛ اینجا برای تشخیص قصد سئویی افراطی استفاده میشود).
lowQuality: اگر متن سطحی، ماشینی یا فاقد عمق باشد، این سیگنال فعال میشود..
اگر محتوا هیچ هدف انسانی نداشته باشد و فقط بر اساس یک کلمهکلیدی نوشته شده باشد، گوگل آن را Search-Engine-First تشخیص میدهد.
آیا در حال تولید حجم زیاد محتوا در موضوعات بسیار متعدد هستید؟
numOfUrlsByPeriods: بررسی میکند سایت در چه فاصله زمانی چهقدر محتوا منتشر کرده.
سایتی که هر روز در دهها موضوع مختلف محتوا میزند، در نگاه گوگل بهسمت «تولید انبوه» میرود و معمولاً کیفیت پایین دارد.
آیا برای تولید محتوا بهصورت گسترده از اتوماسیون و تولید ماشینی استفاده میکنید؟
contentEffort (low): تلاش کم، تولید سریع و محتوای سطحی..
gibberishScores: تشخیص متن ماشینی، بیربط، بههمریخته یا فاقد ساختار انسانی.
مدلهای زبانی اگر بدون نظارت انسانی استفاده شوند، معمولاً همین سیگنالها را فعال میکنند.
آیا فقط حرف بقیه را خلاصه میکنید و ارزش جدید اضافه نمیکنید؟
OriginalContentScore (low): وقتی محتوای شما حرف جدید ندارد یا فقط بازنویسی منابع است.
contentEffort (low): کمتلاشی و نبود تحقیق/تحلیل.
اگر فقط جمعبندی منابع دیگر هستید، نه ارزش افزوده دارید و نه کیفیت.
آیا فقط چون موضوعی ترند شده دربارهاش مینویسید، نه چون برایتان مهم است؟
siteRadius (high): هرچه تنوع موضوعات سایت بیشتر و غیرطبیعیتر باشد، شعاع محتوایی بزرگتر است.
سایتی که امروز درباره سئو مینویسد، فردا رژیم غذایی، پسفردا کریپتو و بعدش فستفود…
نمونه کلاسیک Search-Engine-First است.
آیا محتوای شما باعث میشود کاربر دوباره سرچ کند؟ (pogo-sticking)
badClicks: نشان میدهد کاربر بعد از ورود سریع برمیگردد.
serpDemotion: وقتی رضایت پایین باشد، صفحه مستقیماً افت رتبه میگیرد.
اگر کاربر احساس کند جواب کامل نگرفته، گوگل نتیجه را «غیرمفید» برچسب میزند.
آیا تاریخ محتوا را تغییر میدهید بدون اینکه محتوا واقعاً تغییر کرده باشد؟
lastSignificantUpdate: آخرین تغییر واقعی محتوا.
bylineDate: تاریخ اعلامشده در صفحه.
اگر تاریخ صفحه را تازه کنید اما محتوا همان باشد، گوگل این رفتار را تشخیص میدهد و بهعنوان تلاش برای فریب Freshness در نظر میگیرد.
آیا محتوا درباره موضوعات YMYL است؟ (Your Money or Your Life)
ymylHealthScore: ارزیابی کیفیت صفحات حوزه سلامت/پزشکی.
ymylNewsScore: ارزیابی کیفیت صفحات حوزه اخبار، مالی، حقوقی، امنیت.
اگر موضوع YMYL باشد و محتوا:
- عمق نداشته باشد
- نویسنده متخصص نباشد
- منابع ضعیف باشد
- یا اشتباه factual داشته باشد
سختترین امتیازدهی را میگیرد و سریعترین افت را تجربه میکند.
خلاصه کلام::
اگر محتوایی صرفاً به خاطر ترند بودن، تولید سریع، تولید انبوه یا هدف گرفتن یک کلمهکلیدی ساخته شده باشد،
از نظر گوگل Search-Engine-First است
و سیستمهایی مثل spamrank، badClicks، gibberishScores و numOfUrlsByPeriods آن را تشخیص میدهند.
این نوع محتوا پایدار نیست؛
یا ایندکس میشود و رشد نمیکند،
یا رشد اولیه دارد و بعد از آپدیتها سقوط میکند.
شناخت E-E-A-T و نقش Quality Rater Guidelines
(Get to Know E-E-A-T and the Quality Rater Guidelines)
در این بخش گوگل توضیح میدهد که چرا E-E-A-T مفهومی کلیدی در کیفیت محتواست و چطور سیستمهای خودکار، پس از شناسایی محتوای مرتبط، آنهایی را که «مفیدتر» و «قابل اعتمادتر» هستند، در اولویت قرار میدهند.
این بخش یکی از صریحترین اعترافهای گوگل درباره اهمیت اعتماد (Trust) در رتبهبندی است.
گوگل میگوید برای تشخیص کیفیت واقعی محتوا، از ترکیبی از عوامل استفاده میشود که چهار جنبه اصلی را نشان میدهند:
- تجربه (Experience)
- تخصص (Expertise)
- مرجعیت (Authoritativeness)
- اعتماد (Trustworthiness)
اما نکته کلیدی اینجاست:
در میان همه این جنبهها، اعتماد مهمترین است.
سیگنالهای اصلی:
Q*: امتیاز کیفیت/اعتماد صفحه؛ مهمترین سیگنال در این بخش
siteAuthority: اعتبار کلی دامنه و میزان شناختهشدن سایت در موضوع مرتبط
predictedDefaultNsr: پیشبینی ارزش صفحه نسبت به رقبای مشابه؛ تشخیص اینکه آیا صفحه «قابل اعتمادتر» از سایر نتایج است یا نه
این همان ترکیبی است که در لیک Content Warehouse هم دیده میشود.
اعتماد، محور E-E-A-T
در دادگاه DOJ، مهندس HJ Kim شهادت داد:
سیگنال Q که نشاندهنده کیفیت و اعتماد صفحه است، فوقالعاده مهم است.
یعنی:
- تجربه، تخصص و مرجعیت اهمیت دارند
- اما همگی در نهایت برای تقویت «اعتماد» استفاده میشوند
- اگر اعتماد نباشد، سایر مؤلفهها وزن زیادی ندارند
گوگل به محتوایی رتبه میدهد که از نظر رفتاری، ساختاری و محتوایی «قابل اعتماد» باشد.
آیا E-E-A-T یک «فاکتور رتبهبندی» است؟
گوگل میگوید:
«E-E-A-T یک فاکتور تکی نیست.»
یعنی مثل PageSpeed یا HTTPS یک سیگنال واحد ندارد.
اما سیستمهای رتبهبندی از ترکیب چندین سیگنال استفاده میکنند تا تشخیص دهند صفحه چقدر:
- تجربه واقعی دارد
- تخصص دارد
- مرجعیت دارد
- و قابل اعتماد است
پس E-E-A-T بیشتر یک چارچوب رتبهبندی است تا یک سیگنال واحد.
E-E-A-T در YMYL اهمیت دوچندان دارد
برای موضوعاتی که مستقیماً روی:
- سلامت
- امنیت
- پول
- رفاه اجتماعی
- تصمیمات حیاتی
اثر میگذارند، گوگل وزن بیشتری روی E-E-A-T میگذارد.
سیگنالهای مرتبط:
ymylHealthScore: کیفیت محتواهای حوزه سلامت و دارو
ymylNewsScore: کیفیت محتواهای خبری، مالی، حقوقی و حساس
اگر محتوا YMYL باشد و E-E-A-T ضعیف داشته باشد، حتی اگر ظاهر متن خوب باشد، رتبهگیری بسیار سخت میشود.
نقش Quality Raters چیست؟
گوگل توضیح میدهد که ریتِرها رتبه را تعیین نمیکنند؛ بلکه:
- تغییرات الگوریتم را تست میکنند
- به گوگل بازخورد میدهند که نتایج «بهتر» شده یا بدتر
- E-E-A-T را طبق گایدلاین ارزیابی میکنند
مثل مشتریای که فرم رضایت رستوران را پر میکند:
نه غذا را میپزد
نه دستور پخت را عوض میکند
فقط بازخورد میدهد.
همین بازخوردها کمک میکند سیستمهای گوگل به سمت نتایج با E-E-A-T قویتر حرکت کنند.
چرا خواندن Quality Rater Guidelines مهم است؟
- چون این سند توضیح میدهد:
- یک ریتِر چطور اعتماد را ارزیابی میکند
- چه چیزی نشاندهنده تخصص واقعی است
- کدام الگوها نشانه محتوای ضعیفاند
- چه صفحهای «مفید» محسوب میشود
اگر این معیارها را بشناسید، میتوانید:
- محتوای خود را از منظر E-E-A-T ارزیابی کنید
- نقاط ضعف را پیدا کنید
- ساختار محتوا را با سیگنالهای واقعی گوگل همراستا کنید
گایدلاینها «نقشه مرجع» هستند و سیگنالهای الگوریتم، «زبان اجرای واقعی» این نقشه.
سه پرسش طلایی گوگل درباره محتوا: چهکسی، چگونه و چرا؟
(Ask “Who, How, and Why” About Your Content)
این بخش از گایدلاین، یکی از مهمترین قسمتهای کل سند است.
گوگل خیلی شفاف میگوید برای تشخیص محتوای معتبر و قابل اعتماد، سه سؤال بنیادی را بررسی میکند:
- چهکسی؟
- چگونه؟
- چرا؟
این سه سؤال ستون فقرات E-E-A-T هستند.
چهکسی محتوا را ساخته؟ (Who)
گوگل میگوید یکی از سادهترین راههای تشخیص اعتماد، این است که مشخص باشد نویسنده کیست.
سؤالهای کلیدی:
- آیا مشخص است چه کسی این محتوا را نوشته؟
- آیا صفحه بایلاین دارد (نام نویسنده)؟
- آیا نام نویسنده به پروفایل یا اطلاعات تکمیلی لینک شده؟
سیگنالهای مرتبط:
isAuthor: وجود نویسنده واقعی و قابل تشخیص
authorObfuscatedGaiaStr: سیگنال مخفیسازی نویسنده
authorReputationScore: امتیاز شهرت و اعتبار نویسنده
اگر نویسنده را شفاف معرفی کنید، صفحه از نظر E-E-A-T قویتر میشود؛
اگر این بخش مبهم باشد، اعتماد ضربه میخورد.
محتوا چگونه ساخته شده؟ (How)
کاربر باید بداند این محتوا چگونه تولید شده تا بتواند اعتماد کند.
نمونه:
- در نقد محصول، مهم است که:
- چند محصول تست شده؟
- تستها چطور انجام شده؟
- نتایج چیست؟
- چه شواهدی (عکس، جدول، اسکرینشات) وجود دارد؟
سیگنالها:
productReviewPUhqPage: کیفیت تست واقعی محصولات
productReviewPPromotePage: تشخیص نقدهای تبلیغی در مقابل نقدهای واقعی
original_media_score: اینکه تصاویر/مدیا واقعاً تولید شده یا از جاهای دیگر برداشته شده
docImages: تحلیل تصاویر همراه صفحه.
برای سایر انواع محتوا هم «چگونه» مهم است؛ مخصوصاً وقتی پای اتوماسیون و AI وسط باشد.
سؤالهایی که باید به آنها جواب بدهید:
- آیا روشن کردهاید از اتوماسیون یا AI استفاده شده؟
- آیا توضیح دادهاید چرا از AI استفاده کردهاید؟
- آیا روند تولید و نقش انسان در آن شفاف است؟
گوگل میخواهد بداند:
این محتوا از کجا آمده و چهقدر کار واقعی پشت آن بوده؟
چرا این محتوا ساخته شده؟ (Why)
این مهمترین سؤال است.
گوگل میگوید:
هدف اصلی محتوا باید کمک به کاربر باشد.
اگر هدف اصلی:
- گرفتن ورودی از گوگل
- تست الگوریتم
- پرکردن سوراخهای کلمهکلیدی
باشد، محتوا از دید الگوریتمها ارزش خود را از دست میدهد.
سیگنالهای مثبت:
lastLongestClicks: نشان میدهد کاربر واقعاً از محتوا استفاده کرده
goodClicks: کلیکهای همراه با رضایت و ماندگاری
اگر «چرا» صرفاً سئو باشد: SpamBrain فعال میشود. DocLevelSpamScore امتیاز اسپمی صفحه بالا میرود.
اگر محتوا برای انسان ساخته شده باشد، گوگل تشویق میکند؛
اگر برای الگوریتم ساخته شده باشد، گوگل تنبیه میکند.
خلاصه کلام:
سه سؤال طلایی:
- چهکسی این را نوشته؟
- چگونه نوشته شده؟
- چرا نوشته شده؟
اگر این سه پاسخ شفاف داشته باشند، صفحه شما در مسیری قرار میگیرد که سیستمهای گوگل دوست دارد آن را پاداش دهد.
چرا به «استنتاج خلاق» نیاز داریم؟
(ضرورت Creative Inference Optimisation)
این بخش توضیح میدهد چرا برای فهم ارتباط بین گایدلاینهای گوگل و اطلاعات لیکشده، باید از یک روش استنتاجی استفاده کنیم.
گوگل دفترچه راهنما را منتشر نکرده؛ فقط «قطعات پازل» را میبینیم.
پس تنها راه، کنار هم گذاشتن شواهد و ساختن یک مدل منطقی از سازوکار رتبهبندی است.
۱. نقشه داریم، دفترچه راهنما نه
(The Missing Instruction Manual)
لیک Content Warehouse فقط «بلوکهای اصلی» را نشان داده است:
- نام سیگنالها
- ساختار متادیتا
- ارتباط برخی سیستمها
- شاخصهای رفتاری
- معیارهای کیفیت در سطح مهندسی
اما نحوه استفاده از این سیگنالها منتشر نشده.
گوگل هیچوقت نمیگوید:
- این متغیر برای E-E-A-T است
- این سیگنال این مقدار وزن دارد
- این معیار دقیقاً چگونه روی رتبه اثر میگذارد
ما فقط نامهای خام را داریم:
- contentEffort
- siteAuthority
- predictedDefaultNsr
- spamrank
- Q*
اما نمیدانیم دقیقاً کجا و چگونه استفاده میشوند.
پس ناچاریم از روی شواهد، «دفترچه راهنما» را استنتاج کنیم.
۲. فاصله بین حرفهای رسمی و واقعیت مهندسی
(Bridging the Gap)
گوگل در گایدلاینهای عمومی، از مفاهیم انسانی استفاده میکند:
- تلاش
- عمق محتوا
- تجربه
- تخصص
- اعتماد
- مفید بودن
اما در سیستمهای داخلی، همین مفاهیم تبدیل میشوند به:
- contentEffort
- siteAuthority
- goldminePageScore
- Q*
- lastLongestClicks
- badClicks
- spamrank
برای پر کردن این گپ باید تشخیص دهیم هر مفهوم انسانی دقیقاً در برابر کدام متغیر مهندسی قرار میگیرد.
این همان کاری است که Creative Inference Optimisation انجام میدهد.
در پرونده DOJ هم اشاره شده بود:
«در لیک، وزنها و منحنیها وجود نداشت.»
یعنی:
- سیگنالها را داریم
- اما آستانهها را نمیدانیم
- شکل تأثیر (خطی/غیرخطی) را نمیدانیم
- توزیع وزنها مشخص نیست
این بخش از تحلیل، نیازمند استنتاج حرفهای است.
۳. تفسیر مبتنی بر شواهد، نه حدس
(Evidence-Based Interpretation)
با اینکه:
- اسناد لیکشده واقعیاند
- نام سیگنالها واقعی است
- ساختارها واقعی است
اما «ارتباط» بین آنها باید با استدلال ساخته شود.
مثلاً وقتی میگوییم:
siteAuthority <=> Q*
این یک حدس بیپایه نیست؛
بر اساس:
- ساختار متغیرها
- کاربرد آنها در کد
- تناسب مفهومی با گایدلاینها
- شواهد موجود در DOJ
- و تحلیل مهندسی سیگنالها
استنتاج میشود.
این روش صنعت سئو را از: «حدس زدن و تئوریبافی» به «مدلسازی مبتنی بر شواهد» منتقل میکند.
منابع :
Search Quality Evaluator Guidelines